Simple NLP – 3
Author: Jerry Li
“Siri, what is zero divided by zero?”
“Imagine that you have zero cookies, and you split them evenly among zero friends, how many cookies does each person get? See? It doesn’t make sense. And Cookie Monster is sad that there are no cookies. And you are sad that you have no friends.”
A Brief History – Early Machine Translation
Last time we talked about the birth and the initial difficulties in NLP research from 1940s to 1960s. NLP Research continued in other countries after United States government withdrew funding in the US. According to “Machine translation: a concise history”, the METEO System was developed in Canada for translating weather forecasts between English and French. It was formally adapted in the 1980s to replace junior translators. Systran was a translation system developed in 1968 to support translation among European languages. It was first installed in 1970 and used in intergovernmental institutions including NATO and International Atomic Energy Authority, as well as international companies such as General Motor.
If you remember ELIZA the chat bot from last time, it may seem like Machine Translation systems will never be feasible in such a short period of time. How did METEO System and Systran work? Did the US government greatly misjudged the level of difficulty of NLP? To answer those questions, we need to know how early machine translation systems works.
Machine Translation in Three Steps
The very first automatic translation systems usually translate sentences one by one (which is still true for most translation software today). For each sentence, it consists of three separate steps:
- Extract syntactic (grammar) information from the sentence.
- Reassemble the syntactic structure per the target language.
- Translate each word in source language into target language.
The system resembles a simplified translation procedure of a bilingual human. Since those three steps will reappear again and again in NLP systems developed later, let’s go through them one by one.
Suppose we are working for the Canadian government on translating their weather reports. We are given the sentence “The weather in Montreal is cloudy.” and we would like to translate that into French. I personally know no French and I am not a native English speaker, so I’ll do it the slow way. What I have in hand was an English to French dictionary, an introductory grammar book, and a friend of mine George who knows a little French.
Extract syntactic (grammar) information from the sentence
Part of Speech
The first thing I need is the Part of Speech(POS) for each word. Words are separated into different POS based on how they function grammatically in language, like Nouns, Verbs, Adjectives, etc. I go through the dictionary and look up the first word “The”. It tells me that “The” is a Determiner, a part of speech that also includes “a” and “an”. I go to the next word “weather” and do the same thing. Soon I labeled all part of speech for the sentence: “The/DT weather/NN in/IN Montreal/NNP is/VBZ cloudy/JJ ./.”. Don’t worry if you don’t know what all those DT, NN, and other tags stands for, because I didn’t either. Those are abbreviations of English Parts of Speech. For a complete list of English POS tags please visit here.
Parse Tree
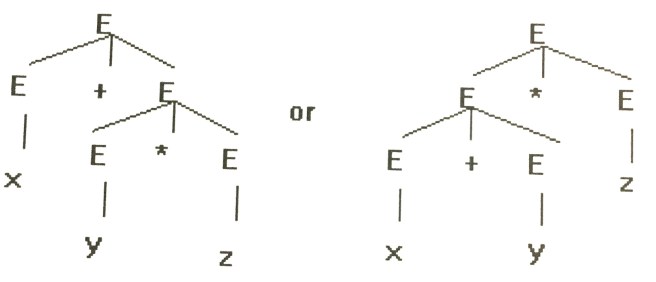
The next thing I need is a parse tree for the sentence. A parse tree represents the grammar structure of a given piece of text. To make things easier, let’s first take a look at parse trees for Math expressions, which are, believe it or not, actually much simpler than those for language. For computing x + y * z, you know that you first need to compute y * z before doing the addition. The parse tree indicates whether to do the addition first or the multiplication first. It works the same way when applied to natural languages – it tells you things like which noun is the adjective modifying and which is the subject of the sentence.
The correct parse tree for x + y * z is on the left. The right one represents (x + y) * z instead.
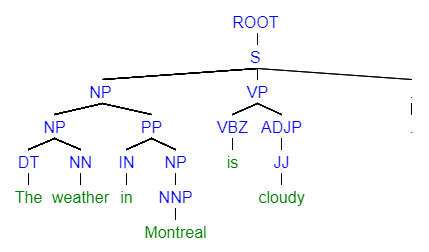
Going back to our example “The weather in Montreal is cloudy.” , I know intuitively the word “The” and the word “weather” should go together, because “The” is the determiner for the noun “weather”. According to the grammar book, Determiner + Noun => Noun Phrase, or if you write it in the fancy way like a linguist, DT + NN =>NP. Similarly, I know “in” and “Montreal” should go together and the grammar book told me Preposition + Noun Phrase => Preposition Phrase. I repeat the process until I reach the final step: Noun Phrase + Verb Phrase + . => A complete sentence! The whole parse tree drawn out looks something like the graph below:
Parse tree for “The weather in Montreal is cloudy.”
Reassemble the syntactic structure into that of the target language
Now I need to turn the parse tree into French sentence structure. I ask my friend George: “What is the corresponding sentence structure for this parse tree?” He looked at it for a second, then kindly replied “Same thing as in English. You know there’s a thing called Google Translate, right?” Ignoring his comment, I copied down “The/DT weather/NN in/IN Montreal/NNP is/VBZ cloudy/JJ ./.”. If you ignore the English words and just look at the POS tags, those will be the sentence structure in French, which happens to be the same as in English for this sentence.
Translate each word in source language into target language
I take out my English to French dictionary and look up the French word for “The”. It gave me “La”. Then I went on to “weather” and it gave me “météo”. I repeated until I have a translation for all the words. It ended up looking like: “La/DT météo/NN à/IN Montréal/NNP est/VBZ nuageuse/JJ ./.”. After I remove the POS, it becomes “La météo à Montréal est nuageuse.” and it looks correct.
Finite State Machine and Dictionaries
In the sections above, we showed how the three-step machine translation system works. In addition, we introduced two important linguistic concepts: Part of Speech (POS) and parse tree. POS tells us whether a word is a Noun, a Verb, or something else. A parse tree is a structure that resembles the relations among words we have in our mind. Additionally, in each of the three steps we’ve made some assumptions about the resources we have at hand.
In the first step, we assumed that we have a dictionary that we can look up a word for its POS. Previously we talked about that words can have different meanings and/or part of speech, but because we are only translating for one specific topic, as in the case of the METEO System, words and their POS usually have little ambiguity. Therefore, we can store a POS dictionary in the machine without having to worry about choosing the correct POS out of many other possible ones.
Next, after tagging the POS for each word, we constructed a parse tree of the sentence. As humans, we know which word goes along with which – the correct parse tree makes sense. But for a machine, it has to rely on rules and logic, and it has to have an internal state to record things like “Did I see a verb? Is the sentence missing an object? I just saw a ‘the’ so I should be expecting a noun next.”. If a machine contains internal states and operates according to a set of rules and logics that allows transition among states, it is called a Finite-State Machine (FSM).
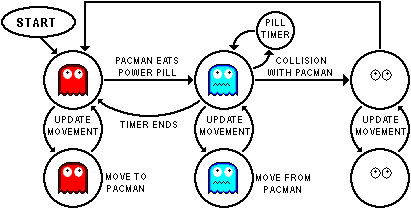
The best examples for understanding FSM are in video game AI. Take Pacman for example, the FSM controlling each enemy unit in Pacman basically has only 7 states and it decides to chase or avoid Pacman based on whether Pacman ate a pill or not. “Chase Pacman” and “avoid Pacman” are states and “Pacman ate a pill” is a transition rule. Once a transition rule is satisfied, it will take the machine to a new state. The FSM for language is more complicated than Pacman AI, but it works the same way – in each step the machine starts in your current state, checks the rules and see which one fits the current situation, proceeds to the next state, check the rules again, and repeat this until a terminal state is reached. FSM is widely used in Computer Science and you should look it up if interested.
Pacman AI FSM
Going back to machine translation, we just used the FSM to generate a parse tree. Then in the second step, we introduced my friend George who derived the French grammar structure from a parse tree. Sadly, the machine translation system did not have any friends, but the same job can also be done by an FSM. Previously we used an FSM to construct a parse tree from a sentence. Now the task is just the other way around. The input now is the parse tree and the output is the sentence order written in the target language. There isn’t much technical difference one way or the other.
Lastly, I used a English-French dictionary. Similar to the POS dictionary we used in the first step, the machine can store and use such dictionary easily, without worrying about ambiguity issues. We’ve went through all the resources we’ve used in our three-step translation system. Now a machine can use FSM and dictionaries to do translation for us.
Downsides of FSM
Comparing ELIZA to machine translation systems like METEO, we can see that replacing pattern matching with FSM worked. It was compact enough to be fit into a computer at that time and the system was robust enough to handle tasks confined to a certain domain. But were there downsides of the FSM? Why can’t we apply the same system to a wider range of tasks other than translating weather reports or government documents?
One of the main problem for FSM is that it needs programmers and scientists to write the rules and states. Furthermore, the quality of the rules and states directly correlate with the ultimate quality of the output. If the rules are too specific, they will only work for a small number of sentences. Researchers will need to write lots of rules to cover all cases. On the other hand, if the rules are too general, then the system will have a higher rate of error due to the large number of possible situations the rule will be erroneously applied to. It is hard even for experts to find the right balance between quality and quantity. Furthermore, if you want to expand the same system to a broader range of tasks, there will be more possible inputs, which means more ambiguity, more rules to be written to handle them, and more human effort.
Example AI bug from YouTube
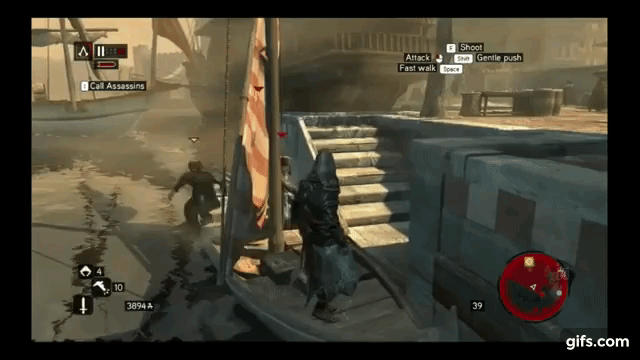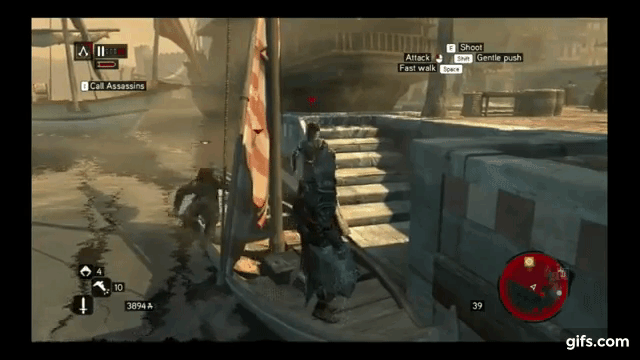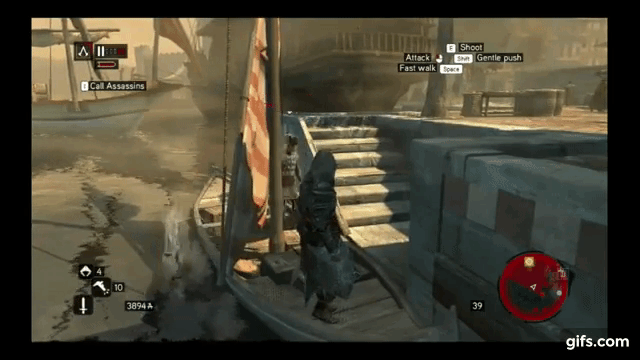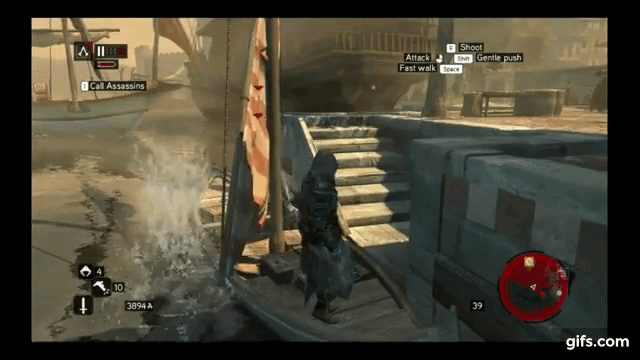
Again, I will use video game AI to illustrate the downsides of FSM. AI in video games needs to handle a lot of complicated situations, which is why they often have bugs. I once saw an AI character in an RPG world who all of a sudden lost its dreams, and start repeatedly running right into the wall for a few seconds, back off, and start running into the wall again. Here’s how a bad FSM-based AI would cause such a bug:
Diagram of a badly designed FSM causing an AI bug

Bounded by the inherent limits in FSM-based NLP systems, an early translation software can only be applied to a specific area. If I want to translate weather reports, I can use software A, but if I want to translate say restaurant menu, I have to switch to software B. Struggling, some Computer Scientists started to wonder: “Can I ask the machines to generate the rules for us when I lie on the couch and chill?” The funny thing is, those people later became the pioneers in Machine Learning. They brought life to NLP as we know of it today and their work will be the topic for my next blog.
P.S.
Formally, the system that used FSM was called Augmented Transition Networks (by Throne, Woods).
Citation
Machine translation: a concise history – John Hutchins
I used the Stanford Parser for parsing the example sentence. I used the Syntax Tree Generator webpage to generate Syntax Tree graphs. I used gif.com to generate the gif from this AI bug video.
Image source:
