The word2vec paper by Mikolov in 2013 (MikolovSCCD13) has drawn attention due to its fast training speed and state of the art performance on analogy and semantic word relationships. It’s model is based on a single hypothesis that the meaning of a word is directly related to the words that appear around it, and by training a neural net to predict the center word based on the context it appears in, we can get a decent model for natural language processing. The word2vec model represents words as high dimensional vectors and train those vectors on large volume of online text (such as wikipedia) to extract the meaning of each word.
Mikolov’s improvement on the neural network model is not only on speeding up training, but also on two by-products: linear representation of linguistic regularities and patterns (MikolovSCCD13) and solving analogy questions using cosine distance (mikolov-yih-zweig:2013:NAACL-HLT).
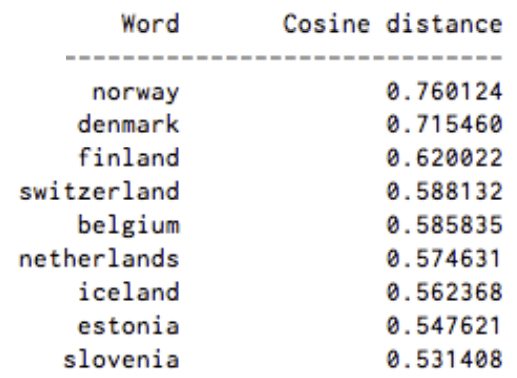
Figure 1: “A list of words associated with “Sweden” using Word2vec, in order of proximity” (From deeplearning4j.org)
A simple example for the linear representation of analogy and semantic information: taking the vectors of words “man”, “woman”, “king”, and “queen” and the closest vector to “king”-“man”+”woman” turns out to be the vector for “queen”. For more detailed explaination about word2vec please refer to word2vec website.
Enter word or sentence (EXIT to break): Chinese river Word Cosine distance ------------------------------------------ Yangtze_River 0.667376 Yangtze 0.644091 Qiantang_River 0.632979 Yangtze_tributary 0.623527 Xiangjiang_River 0.615482 Huangpu_River 0.604726 Hanjiang_River 0.598110 Yangtze_river 0.597621 Hongze_Lake 0.594108 Yangtse 0.593442
Figure 2: “The above example will average vectors for words ‘Chinese’ and ‘river’ and will return the closest neighbors to the resulting vector.” (From word2vec website)
Indeed word2vec model has shown promising results in many analogy and semantics tasks (ZhilaNAACL13). However, it still failed on some analogy tasks such as “banana to yellow as to grass to green”. The fundamental reason behind the failure is because people seldomly mention those facts explicitly in written text and therefore there is no way for the program to know that a normal banana is yellow.
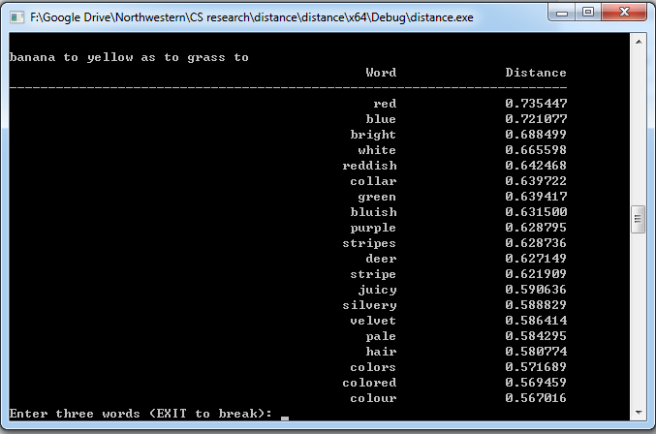
Figure 3: Example of failed analogy task.
My research focuses on improving the current word2vec model by active learning. In other words, by inputting additional human knowledge into the system, we hope to achieve a better performance on analogy.
The other big part of my research is to understand the word2vec model itself. It is hard to improve a model if one does not understand it fully first. Currently the word2vec model is using the cosine distance between two word vectors to measure their similarity. Despite the fact that cosine distance is a common distance measurement for vectors in high dimensions, there seems to be little reasoning why cosine distance would work in a neural network model or why there would be a linear representation of analogies. The original paper did not explain in detail the reason behind using cosine distance (other than emperical reasons).
This is a currently on-going research and I do not have any conclusions yet. But over the past year, I’ve tried enough to hypothesize a few key points that I’ll summarize here:
- The word vectors seems to have the information spread throughout each dimension. (indicated by doing PCA on several semantic categories)
- The mysterious linear property comes from how the neural net is constructed and trained.
- It seems to be hard to move the vectors of some of the words without disrupting the vectors of the whole vocaburary. (indicated by the failed attempts to inserting knowledge by active learning on some specific topics so far)
It has been a really fun and open-ended research so far. The research has tested my understanding of different machine learning techniques and improved my programming skills. Special thanks to my professor Doug Downey, and other researchers who’ve worked with me (David Demeter, Nishant Subramani, Anuj Iravane , and Michael Lucas).
